
The Kaggle playground competition “House Prices” had been good in terms of applying an stacking strategy described in this post before, that you can find in this Git Hub link. It had been used a variety of techniques like Random Forest, GBM, Lasso, Ridge Regression, SVM and XGBoost, not necessarily “weak learners”, an the result was good, this is something to take into account. One of the aspects to highlight is the use of the stacking strategy in this graphic.
An option on STACKING …
A binary classification problem. This is the stacking perspective used:
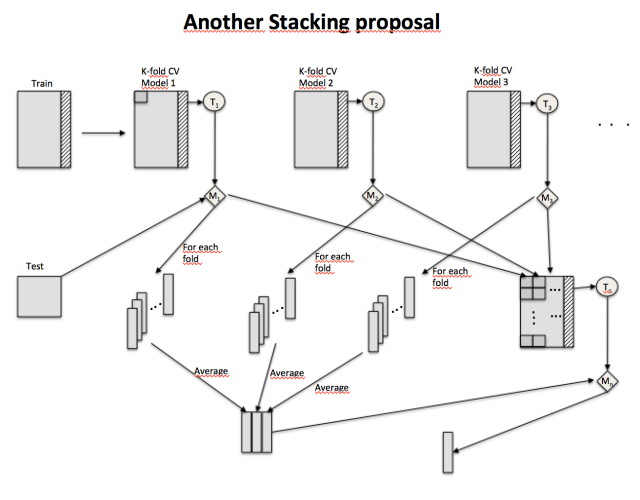
Techniques to use, for example, KNN, Random Forest and SVM.
Cross Validation: 5-fold
Level 0:
Input: Train and test set
For every technique j:
For every fold i:
- Apply the technique to train set minus fold i and get the model.
- Train set: Use the model to get a prediction on fold i
- Test set: Use the model to get prediction on the test set.
Train-stacked set with the j-technique prediction.
Test-stacked set with the i folds prediction average for the j-technique prediction.
Level 1:
Input: Train-stacked set and Test-stacked set
- Train-stacked set: j columns corresponding to each technique cross-validation predictions, with the j+1 target column.
- Test-stacked set: j columns corresponding to each model prediction on the test set.
Then use, for example Logistic Regression to train Train-stacked set, and get the final predictions on the Test-stacked set.
Kaggle: Grupo Bimbo Inventory Demand
It had been a very good experience because of the big files sizes an the possibilities my computer has processing large amount of data, at least for me. The decision of processing the files a week at a time was not a good one, as far as I have seen some results published in the competition, some insights and code can be found here. It was great experience an fun doing Data Science.
Kaggle: Santander Customer Satisfaction – some insigths
Business understanding
From the competition site description:
From frontline support teams to C-suites, customer satisfaction is a key measure of success. Unhappy customers don’t stick around. What’s more, unhappy customers rarely voice their dissatisfaction before leaving.
Santander Bank is asking Kagglers to help them identify dissatisfied customers early in their relationship. Doing so would allow Santander to take proactive steps to improve a customer’s happiness before it’s too late.
In this competition, you’ll work with hundreds of anonymized features to predict if a customer is satisfied or dissatisfied with their banking experience.You are provided with an anonymized dataset containing a large number of numeric variables. The “TARGET” column is the variable to predict. It equals one for unsatisfied customers and 0 for satisfied customers.
The task is to predict the probability that each customer in the test set is an unsatisfied customer.
Some insigths
The data was around 75000 records with 370 features, one more for training, the dependent features called TARGET. Most of data was anonymised and besides from that most of the features have zeros and ones, kind of sparce matrix.
The data was mainly anonymized, and he name of the features made us think that it is an enterprise where Spanish is the base language, like in the case of “saldo” that means balance appear in same of them, and also “amort” that probably means amortization. But besides from that specific set of features most of them were very difficult to identify their meaning. It had been found that some of the features were constants, which were removed from the dataset. Something that showed up was the high correlation we could find in various features, something very unusual when you have a lots of features like in this case. Something that drawn my attention was the fact that this dataset had a very high level of imbalance in the predicted features TARGET.
Because of the variety of features and most of them impossible to identify their meaning, I created some new features that were combinations of existing ones using almost randomly functions like sqrt, log, multiplications and some others, this is a problem when you have mainly anonymized data, because it is not possible to identify some new features if you do not have the meaning of them.
Mainly it had been used XGBoost, something that was amazing was that it could manage this imbalance data very good with come parameter values that I got from the kaggle posts. As a conclusion the main aspect that I learned from this competition is that the problem with imbalance data can be managed with models like XGBoost in a smooth way, and also very happy because this is the second time I am within the 25% of the people who got the highest scores.
Kaggle: Don’t get kicked – some insigths
This competition was very interesting, I had a lot of fun playing with this data. Here you can a find a paper that describes the analysis and insight I worked on.
Kaggle: BNP Paribas Cardif – some insights
Besides from the fact that there were lots of NAs, anonymized feature names and also high levels of correlations, it was very nice to try with different models and different set of features. Something that draw my attention was the fact that the inclusion of highly correlated features in the predictions helped. In this link can be found some thoughts and analysis.
Kaggle: Prudential Life Insurance Assesment – Some insights
The highlight of this competition was that the use of ML models with the dataset considering a number of variables originally of factor type, which did not prove to get higher level of accuracy, but when those variables were transformed to ordinal numerical which made a big difference. The use of linear models also drew attention because the predicted values had to be adjusted by cuts in the discrete range of values 1 to 8. In this link can be found some thoughts and analysis.
Kaggle: Rossman Store Sales – some insights
In this competition something that was very particular was the relevance of a couple of features StoreType and Assortment, either taken them individually or together they really separate the dataset. In the GitHub link can be found some thoughts and analysis
In spite of the variety of information in this dataset few features made a big impact in the prediction, two of the main ones were StoreType and Assortment.
Updating a database
The SQL problems studied in the posts on this site can become a serious trouble when updating a database; I mean update in terms of insert, delete and update as such a database.
There are several possibilities in technology at the time of updating a database, for example, we have the case of input data to an information system, when we are migrating a database to a new one that usually has a different structure, in the case of updating a distributed databases that are spread in different locations, when we are loading data to a Data Mart, and a number of other possibilities, in all of them we must be aware of the danger of inserting data into a database when we don’t know the weaknesses of SQL.
In this case the problems go beyond query results, we know that the only way to update a SQL database is by using the language SQL, in the case of an information system a simple interface could let us put data in it which could erroneous data in database, from there on we could never trust in the query results anymore The possibility of erroneous data in SQL databases is present with standard operations INSERT, UPDATE and DELETE.
These operations may cause incorrect data inserted only in the case of using the Table expressions in the query, I mean using the SELECT expression within the operations INSERT, UPDATE and DELETE.
Essential to know about the weaknesses SQL have.
A detailed explanation plus some other problems found with the SQL aggregate operators is found in my book:
Amazon.com: http://tinyurl.com/amnz-sqlbook
Problems with the SQL operator Average
What is the average of this set of values? 4, 8, 6
The average is 6, the operation is (4+8+6) / 3.
If we use the SQL operator AVG() with that set of values the result is the same six, unless at least one more value appears in the set, I mean the “value” null, then the set become: 4, 8, 6, null
The operation would be? (4+8+6+null) / 3.
Whatever null means in this context, the common sense tells us that this operation using SQL should not give us a numeric answer because of null, maybe some other kind of answer like for ex. “I don’t know”.
The problem is that when a SQL query with operator AVG() has this later set of values the answer is 6, it means that SQL doesn’t consider null as another value, and worse it doesn’t tell us anything else, with the consequence that the answer may be misinterpreted.
We have to be consious about this problem. We can have a database table with a hundred of tuples with one numeric attribute that has the values 4 and 2, and the rest just losts of nulls,
4, 2, null, null, …, null a hundred times
then in an SQL AVG() operation we obtain the result of 3.
Obviously the answer cannot be 3, it makes no sense. Well Ok, SQL calculates (4+2) / 2 = 3, but may SQL tell us that there are losts of nulls not being considered in the operation, but no, SQL doesn’t tell us anything else but the result three.
Some other problems about the operator sum vs. count can be found in my publication:
A detailed explanation plus some other problems found with the SQL aggregate operators is found in my book:
Amazon.com: http://tinyurl.com/amnz-sqlbook
